Cybersecurity and Artificial Intelligence: Challenges & Solutions
1. Vulnérabilités de l'IA
L'essor fulgurant de l'intelligence artificielle constitue aujourd'hui un phénomène d'une ampleur considérable, évoluant à une vitesse remarquable. De l'assistant vocal "Siri" sur nos smartphones au chatbot "ChatGPT", en passant par la reconnaissance faciale utilisée pour déverrouiller nos appareils électroniques, l'intelligence artificielle imprègne de manière omniprésente notre quotidien, offrant une facilité d'utilisation et une puissance extraordinaires. Qui n'a pas recours à "ChatGPT" pour rédiger des messages complexes de nos jours ?
Cependant, comme le soulignait le regretté oncle de Spider-Man, Ben Parker, « With great power comes great responsibility ! » ou « Avec un grand pouvoir vient une grande responsabilité ! » En effet, bien que l'IA représente une création révolutionnaire et puissante, elle s'accompagne d'une responsabilité considérable. Il est impératif de garantir sa sécurité, un domaine qui diffère grandement de ce que à quoi nous sommes habitués aujourd'hui dans le monde de l'informatique.
Quelles sont les raisons pour lesquelles l'intelligence artificielle soulève des enjeux de sécurité ?
Les failles des systèmes d'intelligence artificielle diffèrent notablement de celles que l'on peut rencontrer dans les systèmes plus traditionnels, souvent causées par des "bugs" ou des erreurs humaines. Les attaques sur l'IA, également connues sous le nom d'attaques IA, ciblent plutôt les vulnérabilités résultant des limitations inhérentes aux algorithmes, lesquelles, pour l'instant, restent difficilement réductibles.
Une étude menée par les chercheurs d'Adversa met en lumière les domaines vulnérables exploités pour attaquer les systèmes alimentés par l'intelligence artificielle. Selon leurs conclusions, ce sont principalement les systèmes traitant les données visuelles qui représentent la majorité des cibles d'attaques dans le domaine de l'IA.
Domaines de vulnérabilités
Scénarios d'attaque
Les attaques dirigées contre les systèmes d'intelligence artificielle, communément appelées attaques adversarial attacks, as described by the UC Berkeley Machine Learning team, rely on the creation of illusions. These are manipulative actions and deceptive data designed to fool the AI algorithm, causing the machine to behave unusually or revealing confidential information.
Le fonctionnement de ces attaques diffère des logiciels conventionnels, car les systèmes d'IA utilisent des algorithmes d'apprentissage automatique qui développent leur comportement à travers des actions répétitives et l'expérience. Le problème en termes de sécurité réside dans le fait que ces algorithmes transforment une donnée d'entrée en une donnée de sortie. Par exemple, si un système d'IA reconnaît qu'une image contient un objet spécifique en comparant les pixels de cette image avec ceux d'autres images de l'objet traité pendant son apprentissage, cette caractéristique peut être exploitée pour dérouter l'algorithme.
Voici quelques exemples d'attaques ciblant les domaines de vulnérabilité évoqués précédemment.
- Attaque adversarial contre les systèmes de vision :
En 2018, un groupe de chercheurs a réussi à tromper un système de conduite autonome pour qu'il identifie un panneau d'arrêt comme étant un panneau de limitation de vitesse. La méthode utilisée consistait à manipuler l’image du panneau STOP en ajoutant des pixels, créant ainsi une perturbation invisible à l'œil nu.

Détecté STOP à 57.7%
+ .007 x

=
Détecté Panneau limitation de vitesse 50 à 99. 3%
C'est ainsi que le classificateur d'images GoogLeNet a été induit en erreur,pensant qu'une image clairement représentant quelque chose correspondait en fait à autre chose, selon sa perspective.
- Adversarial attack contre les systèmes de reconnaissance vocale
Les attaques adversarial ne se limitent pas aux systèmes de vision. En 2018, des chercheurs ont démontré que les systèmes de reconnaissance vocale automatisée (ASR) pouvaient également être la cible de telles attaques.
L'ASR est la technologie qui permet à des dispositifs tels qu'Amazon Alexa, Apple Siri et Microsoft Cortana d'analyser les commandes vocales.
Dans ce type d'attaque, un pirate manipule un fichier audio afin d'y intégrer une commande vocale dissimulée, inaudible pour l'oreille humaine. Un auditeur humain ne remarquerait donc pas le changement, mais pour un algorithme d'apprentissage automatique, la modification serait clairement détectable et exploitable. Cette technique pourrait être utilisée pour transmettre secrètement des commandes à des haut-parleurs intelligents.
- Attaque adversarial contre les classificateurs de texte
En 2019, des chercheurs d'IBM Research, d'Amazon, et de l'Université du Texas ont démontré que ce type d'attaques ciblait également les algorithmes d'apprentissage automatique des classificateurs de texte, tels que les filtres anti-spam.
Surnommées "attaques de paraphrase", ces attaques adversarial basées sur du texte consistent à apporter des modifications aux séquences de mots dans un morceau de texte afin de provoquer une erreur de classification dans l'algorithme d'apprentissage automatique.
- Attaque adversarial black-box et white-box
Comme toute cyberattaque, le succès des attaques adversarial dépend de la quantité d'informations dont dispose un attaquant sur le système d'apprentissage automatique ciblé. Selon le niveau d'information détenu, on distingue les attaques en black-box et les attaques en white-box.
Une attaque est qualifiée de black-box lorsque l'attaquant dispose d'informations et d'un accès limités, équivalant ainsi aux capacités d'un utilisateur ordinaire. De plus, l'attaquant n'a aucune connaissance du système ni des données sous-jacentes au service. Par exemple, pour cibler une API accessible au public comme Amazon Rekognition, l'attaquant doit sonder le système en fournissant diverses entrées à plusieurs reprises et évaluer les réponses jusqu'à la découverte d'une vulnérabilité.
Une attaque est qualifiée de white-box lorsque l'attaquant possède une connaissance complète et une transparence totale du système ou des données cibles. Dans ce cas, les attaquants peuvent examiner le fonctionnement interne du système et sont mieux placés pour identifier des vulnérabilités.
Chen, un chercheur, a souligné que "les attaques en black-box sont plus pratiques pour évaluer la robustesse des systèmes de Machine Learning déployés et à accès limité du point de vue d’un adversaire", tandis que "les attaques en white-box sont plus utiles pour les développeurs de systèmes afin de comprendre les limites du système de Machine Learning et d’améliorer la robustesse pendant la formation des systèmes."
Il existe également un autre type d’attaque appelé attaque d’empoisonnement de données..
Dans certaines situations, les attaquants ont accès à l'ensemble de données utilisé pour former le système d'apprentissage automatique. Dans ces cas, les attaquants peuvent mettre en œuvre une technique appelée "empoisonnement des données", où ils introduisent délibérément des vulnérabilités dans le système pendant la phase d'entraînement.
Par exemple, un attaquant pourrait entraîner un système d'apprentissage automatique pour être secrètement sensible à un motif spécifique de pixels, puis le distribuer aux développeurs en vue de son intégration dans leurs applications sans leur connaissance. Étant donné les coûts et la complexité associés au développement d'algorithmes d'apprentissage automatique, l'utilisation de systèmes pré-entraînés est très répandue dans la communauté de l'IA. Une fois le système distribué, l'attaquant exploite la vulnérabilité pour attaquer les applications qui l'ont intégré.
2. Sécurité de l'IA
Méthode de protection de l'IA : Adversarial Training
Au cours des dernières années, des chercheurs en intelligence artificielle ont mis au point diverses techniques visant à renforcer la robustesse des systèmes d'apprentissage automatique face aux attaques adversarial attaques adversarial. La méthode de défense la plus reconnue est l'«adversarial training,” where developers patch vulnerabilities by subjecting the machine learning system to examples of adversarial data during training.
Avec cette approche, les concepteurs d'un modèle génèrent de nombreux adversarial examples pour confronter le modèle à ces cas particuliers, permettant ainsi au système de s'ajuster et de ne plus reproduire ces erreurs à l'avenir.
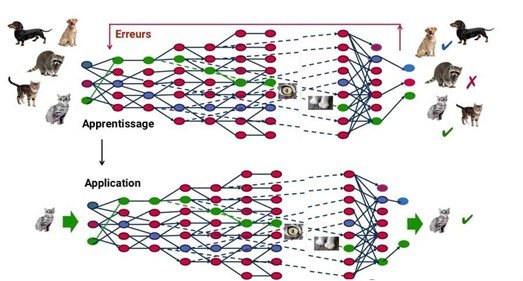
Cette approche repose sur le Deep Learning, une forme d'intelligence artificielle dérivée du machine learning, où la machine se contente d'appliquer rigoureusement des règles préétablies. En utilisant un réseau de neurones artificiels inspirés du fonctionnement du cerveau humain, composé de centaines de couches, chaque couche recevant et interprétant les informations de la couche précédente, le système est capable de reconnaître d'abord les lettres avant de traiter les mots dans un texte, voire même de déterminer la présence d'un visage sur une photo avant d'identifier la personne concernée.
À chaque étape, les « mauvaises » réponses sont éliminées et renvoyées vers les niveaux en amont pour ajuster le modèle mathématique. Progressivement, le programme réorganise les informations en blocs plus complexes. Lorsque ce modèle est ensuite appliqué à d'autres cas, il peut reconnaître un chat sans qu'on lui ait jamais explicitement enseigné le concept de chat. Les données initiales sont cruciales : à mesure que le système accumule diverses expériences, sa performance s'améliore.
Les limitations de cette méthode
Bien que cette approche soit efficace, elle demeure insuffisante pour contrer toutes les attaques en raison de la diversité des possibilités, lesquelles ne peuvent toutes être anticipées. Ainsi, il s'agit d'une course entre les attaquants qui génèrent de nouvelles stratégies et les concepteurs qui entraînent les modèles pour les immuniser contre ces attaques.
En d'autres termes, construire un modèle théorique exhaustif pour anticiper ces exemples est pratiquement impossible. Cela reviendrait à résoudre des problèmes d'optimisation extrêmement complexes, pour lesquels nous ne disposons pas des outils théoriques nécessaires.
Méthode de protection de l'IA: les techniques de masquage de gradient
Comme précédemment mentionné, certaines techniques d'attaque exploitent le gradient d'une image. En d'autres termes, les attaquants prennent une image d'un avion, testent quelle direction dans l'espace de l'image augmente la probabilité que l'image soit reconnue comme un chat, puis perturbent l'entrée dans cette direction en modifiant son gradient. La nouvelle image modifiée est ainsi faussement identifiée comme celle d'un chat.
Cependant, que se passerait-il s'il n'y avait pas de gradient, c'est-à-dire si une modification de l'image ne provoquait aucun changement ? Cette situation semble offrir une certaine défense car l'attaquant ne saurait pas dans quelle direction orienter l'image.
Nous pouvons facilement imaginer des moyens très triviaux de se débarrasser du gradient. La plupart des modèles de classification d'images peuvent fonctionner selon deux modes : un mode où ils produisent uniquement l'identité de l'image la plus probable, et un mode où ils génèrent des probabilités. Si l'image est identifiée comme « 99,9% avion, 0,1% chat », alors une légère modification de l'entrée entraîne un léger changement de la sortie, et le gradient indique quels changements augmenteront la probabilité d'avoir un chat. En revanche, si le modèle est exécuté en mode où la sortie est détectée uniquement comme un avion seulement (l’identité la plus probable seulement), alors une petite modification de l'entrée ne changera pas du tout la sortie, et le gradient ne fournira aucune indication.
Voici comment expliquer cette méthode :
Nous sommes tous d'accord pour dire que cette image représente clairement un avion. À première vue, nous pouvons l'affirmer avec certitude à 100%.
Maintenant, imaginons que notre modèle de classificateur d'images fonctionne en mode probabiliste.
Lorsque nous lui présentons l'image de l'avion en tant qu'entrée, voici le résultat obtenu en sortie :
99.9% avion, 0,1% chat

Maintenant, ajoutons aléatoirement quelques pixels pour observer comment cela pourrait altérer la sortie de notre classificateur :
+ .007 x

Le résultat est maintenant le suivant :
90 % avion, 10 % chat.
Avec ces résultats, l'attaquant peut déterminer « la direction de l’espace » dans laquelle perturber l'entrée en ajoutant des pixels pour accroître la probabilité que l'image soit identifiée comme un chat.
Ensuite, imaginons que notre classificateur d'images fonctionne en mode "image la plus probable", sans la notion de gradient. Présentons-lui à nouveau l'image de l'avion. La sortie du classificateur, dépourvu de la notion de gradient, ne fournira que le résultat le plus probable :
Avion.
En ajoutant des pixels à l'entrée :
+ .007 x

Étant donné que le résultat le plus probable demeure "avion" dans ce cas, la sortie reste inchangée. L'attaquant n'a donc pas la capacité de déterminer comment altérer l'entrée pour tromper notre classificateur.
Les limitations de cette méthode
Bien que cette méthode puisse offrir une certaine défense, elle n'est pas infaillible. En effet, un attaquant pourrait élaborer son propre modèle, un modèle fonctionnant avec le gradient, manipuler des images pour son modèle, puis déployer ces exemples contre le modèle cible. Dans de nombreux cas, le modèle cible serait piégé.
En d'autres termes, l'attaquant entraîne un modèle de substitution : une copie qui imite le modèle cible en observant les sorties du modèle cible pour des entrées soigneusement choisis par l'attaquant. C'est ainsi qu'il pourrait contourner le masquage du gradient.
Méthode de protection de l'IA: la maîtrise des entrées
La méthode de maîtrise des entrées, également connue sous le nom d'augmentation des données, regroupe diverses techniques visant à accroître artificiellement la quantité de données en générant de nouveaux points à partir des données existantes. Cela peut inclure de légères modifications aux données existantes ou l'utilisation de modèles d'apprentissage profond pour créer de nouveaux points. Cette approche vise à améliorer la précision des prédictions du modèle.
La plupart des techniques d'augmentation de données se concentrent principalement sur des modifications visuelles simples.
On pourra parler de :
- Rembourrage
- Rotation aléatoire
- Re-scaling
- Retournement vertical et horizontal
- Recadrage
- Zoom
- Assombrissement et éclaircissement/modification des couleurs
- Grayscaling
- Modification du contraste
- Ajout de bruit
- Effacement aléatoire
Les limitations de cette méthode
Cette méthode se révèle efficace, sauf dans le cas où les données sont restreintes. En effet, dans ces situations, des informations cruciales peuvent manquer, notamment celles provenant des données non utilisées lors de l'entraînement, ce qui peut entraîner des résultats biaisés.
Méthode de protection : distillation
La distillation défensive constitue une méthode d'entraînement visant à renforcer la résilience d'un algorithme de classification, réduisant ainsi sa vulnérabilité aux exploitations. Cette approche consiste à former un modèle pour prédire les probabilités de sortie d'un autre modèle préalablement entraîné sur une base standard, augmentant ainsi la précision du processus.
Lorsqu'un modèle est entraîné pour atteindre une précision maximale, par exemple avec un seuil de probabilité de 100%, il peut présenter des lacunes, car l'algorithme ne traite pas chaque pixel pour des raisons de temps. Si un attaquant apprend quelles fonctionnalités et paramètres le système analyse, il pourrait envoyer une image incorrecte avec seulement les pixels pertinents pour tromper le modèle.
Dans le cas de la distillation, le premier modèle indique une probabilité de 95% qu'une empreinte digitale corresponde à l'analyse biométrique enregistrée. Cette incertitude est ensuite utilisée pour entraîner un deuxième modèle, agissant comme un filtre supplémentaire. Avec l'introduction d'un élément aléatoire, le deuxième algorithme, également appelé "algorithme distillé", devient beaucoup plus robuste, ce qui lui permet de détecter plus facilement les tentatives d'usurpation.
Les limitations de cette méthode
Le principal inconvénient de cette approche réside dans le fait que, bien que le deuxième modèle bénéficie d'une plus grande souplesse pour rejeter les manipulations d'un attaquant, il demeure néanmoins contraint par les règles générales du premier modèle. Ainsi, avec une puissance de calcul suffisante et des ajustements appropriés de la part de l'attaquant, les deux modèles peuvent être rétro-conçus pour découvrir des vulnérabilités fondamentales.
De plus, les modèles de distillation sont sujets aux attaques d'empoisonnement, où la base de données de formation initiale peut être corrompue par un acteur malveillant.
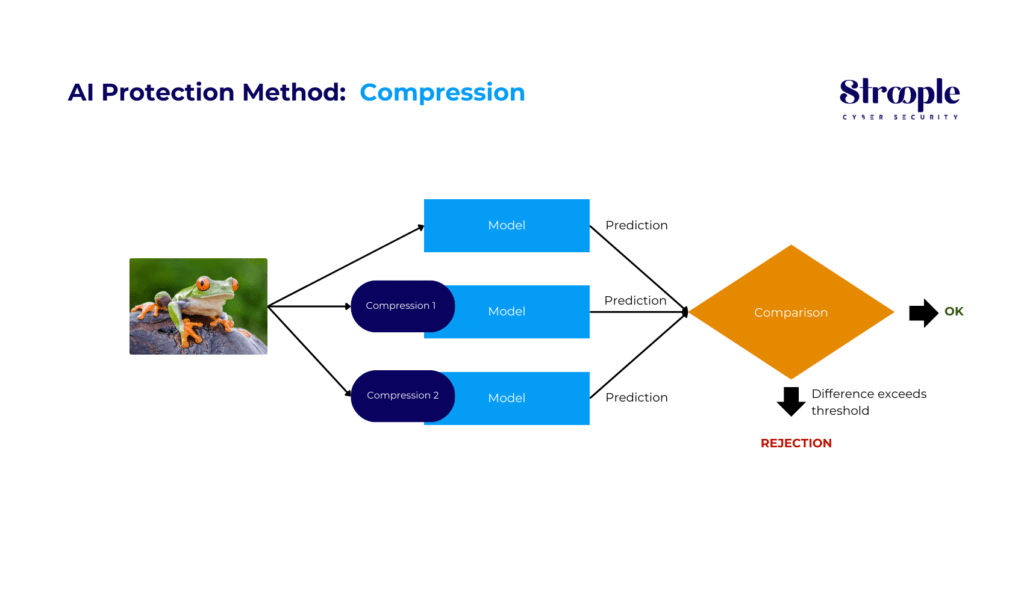
Méthode de protection de l'IA : Compression
La technique de compression s'avère efficace pour repérer attaques adversarial en comprimant une entrée de diverses manières et en la soumettant au même modèle. Les résultats obtenus sont ensuite comparés, et si les entrées compressées génèrent des sorties sensiblement différentes de l'entrée non modifiée, cela indique la détection d'une attaque.
En quantifiant le désaccord entre les prédictions et en établissant un seuil, notre système génère des prédictions précises pour les exemples légitimes tout en rejetant les entrées provenant d'une attaque.
Les limitations de cette méthode
Cette approche n'est efficace que contre des attaquants statiques qui ne s'ajustent pas pour cibler directement la méthode de compression. Cependant, si les attaquants parviennent à s'adapter, ils peuvent identifier une entrée produisant une sortie incorrecte tout en maintenant un score de comparaison entre les prédictions du modèle pour les entrées compressées et l'entrée non compressée en deçà du seuil de détection.
En conclusion, l'évolution rapide de l'intelligence artificielle a révolutionné de nombreux aspects de notre vie quotidienne et professionnelle. Cependant, cette avancée technologique n'est pas sans risques. Comme nous l'avons vu, l'IA est susceptible à une multitude de vulnérabilités de sécurité, allant des attaques adversarial aux empoisonnements de données. Les méthodes de défense actuelles, telles que l'entraînement adversarial, les techniques de masquage de gradient, la maîtrise des entrées, la distillation et la compression, offrent des solutions partielles et spécifiques, mais aucune d'entre elles ne constitue une panacée.
Face à ces défis, il est clair que la sécurité dans l'IA est un domaine en constante évolution, nécessitant une vigilance et une innovation permanentes. Les chercheurs et les développeurs doivent continuer à collaborer pour concevoir des systèmes d'IA plus robustes et sécurisés. En parallèle, il est impératif de développer une compréhension plus profonde des vulnérabilités de l'IA pour anticiper et contrer efficacement les nouvelles menaces.
L'avenir de l'IA dépendra en grande partie de notre capacité à sécuriser ses fondations et à éduquer les utilisateurs sur les risques potentiels. En adoptant une approche proactive et en investissant dans la recherche et le développement en matière de sécurité, nous pouvons espérer naviguer avec succès dans ce labyrinthe complexe de vulnérabilités, assurant ainsi un avenir plus sûr et plus fiable pour l'intelligence artificielle.
Face à ces défis en constante évolution, il est essentiel de s'entourer d'experts en cybersécurité. Stroople, en tant que pure player dans le domaine de la cybersécurité, se positionne comme le partenaire de confiance pour accompagner ses clients dans la sécurisation de leurs activités numériques face à l'évolution rapide de la cybermenace.
